
关于MySQL的几道面试题
关于MySQL的几道面试题
一、介绍
MySQL大家都很熟悉了,最常用的开源数据库,也是面试官高发常问的技术。
简单列出几道MySQL的几道面试题,一起来看看
-
B树和B+树之间的区别是什么
-
Innodb中的B+树有什么特点 -
Innodb中的索引和B+树 -
B+树可以存储多少的数据
-
索引类型有哪些
-
索引失效的场景
二、问题
1)B树和B+树之间的区别是什么
大家都知道,MySQL中使用存储数据的结构是B+树,那么他和B树有什么区别吗?
首先我们得先了解什么是B树,先看看B树的一些概念
排序方式:所有节点储存都是有序的,都遵循左小右大的原则进行排序
子节点数:非叶节点的子节点数>1,且<=M ,且M>=2
- M是什么:在B树中,一个的子节点数目的最大值,即为M。这颗树也称为M阶数
关键字数:枝节点(B树中去除掉根节点和叶子节点的剩余节点)内的关键字数>=
ceil(M/2),且<M-1
- 关键字数K:
ceil(M/2)<=K<=M-1- ceil函数:天花板,向正方向取整
- M:枝节点的子节点数量
叶子节点:所有的叶子节点都在同一层,也就是最后一层都应该是叶子节点
好的,概念就这些,简单画一个B树出来

这些概念和公式不用记,我们直接来看B+树
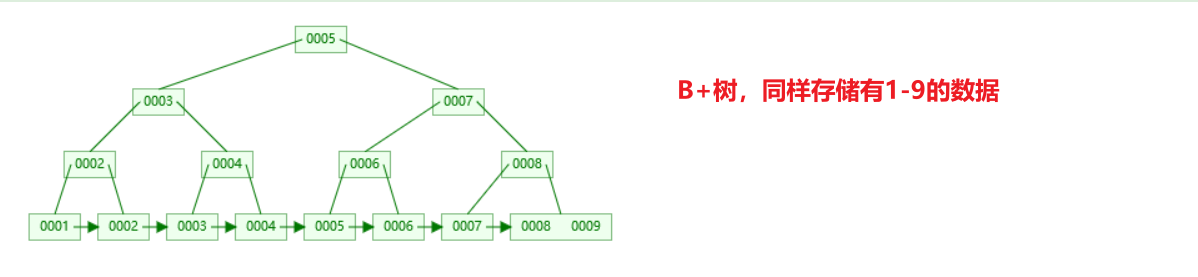
B树和B+树的区别
-
叶子节点:每个叶子节点都多出了个指针,指向下一个叶子节点。
-
非叶子节点:非叶子节点中的元素存储的都是,在叶子节点中出现过的。
- 也就是说:叶子节点,保存了所有的数据。非叶子节点中的数据是冗余的
看完了上面B树和B+树,也可以总结出他们的区别。B+树也就是B树的升级版,对原本的B树做出的一些升级。
2)Innodb中的B+树有什么特点
在上一段中,简单说了一下B树和B+树的区别,但没有对Innodb的B+树展开详细的说明。
看看官网,MySQL的B+树和上面举例的B+树还不完全一样
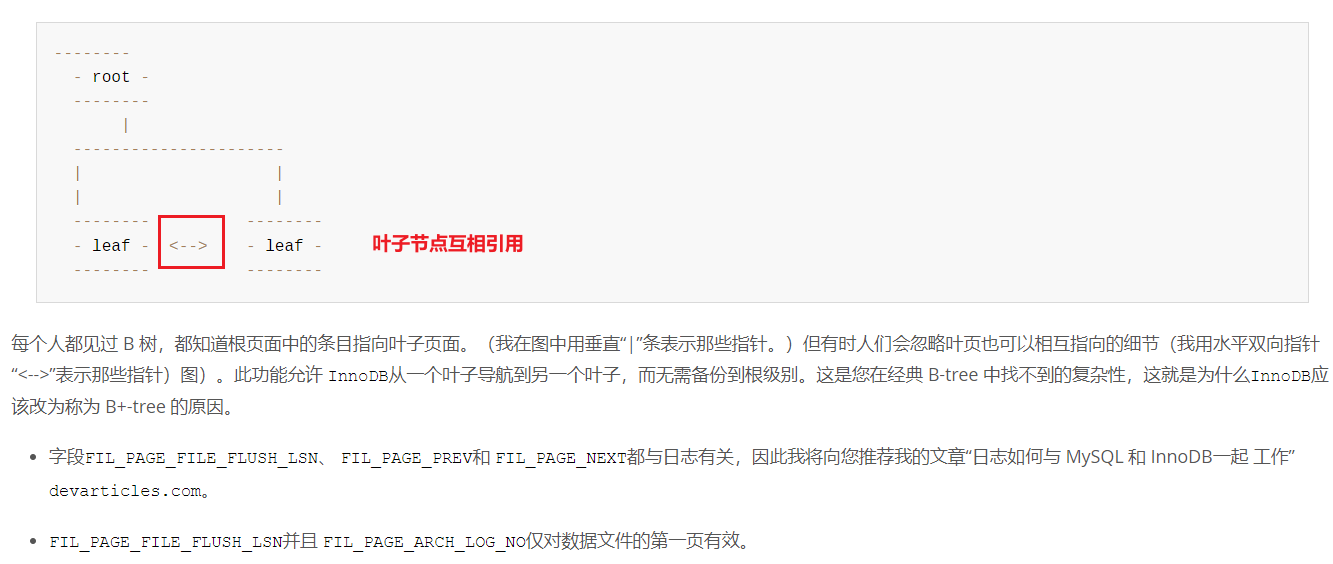
所以Innodb使用的B+树,实际上就是对B树的做出的一定升级改动。
但为什么要这么改呢,简单的来说,就是为了索引。
那么B+树和索引有什么关系呢,继续看下一章
3)Innodb中的索引和B+树
我们来进行模拟实验一下,创建一张数据表,并将数据进行插入
1 | CREATE TABLE `test` ( |
执行完成后,查询表select * from test,查看结果
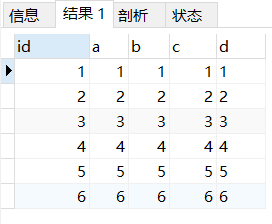
大家要注意插入的主键ID顺序是乱序的,可结果出来的确实按照主键ID进行了排序,按理来说,应该会是我插入的顺序进行展示。但结果确实有顺序的,一定在某个时刻进行了排序
那么是在什么时候进行的排序,是在插入的时候,还是在查询的时候?
结果一想可知,一定是插入的时候,因为查询效率是高性能数据库最重要的指标之一,不可能放在使用的时候去处理这么繁琐的工作。
那么MySQL是如何存储这些数据的呢,还记得B+数的节点吗,在Innodb的这颗B+树中,节点被称为页,一页是16kb,而MySQL在进行数据检索时,每一次进行磁盘IO都会拉取一页的数据,也就是一次读取16kb的数据,进行查找。
简单看看这单个页中都有什么数据。
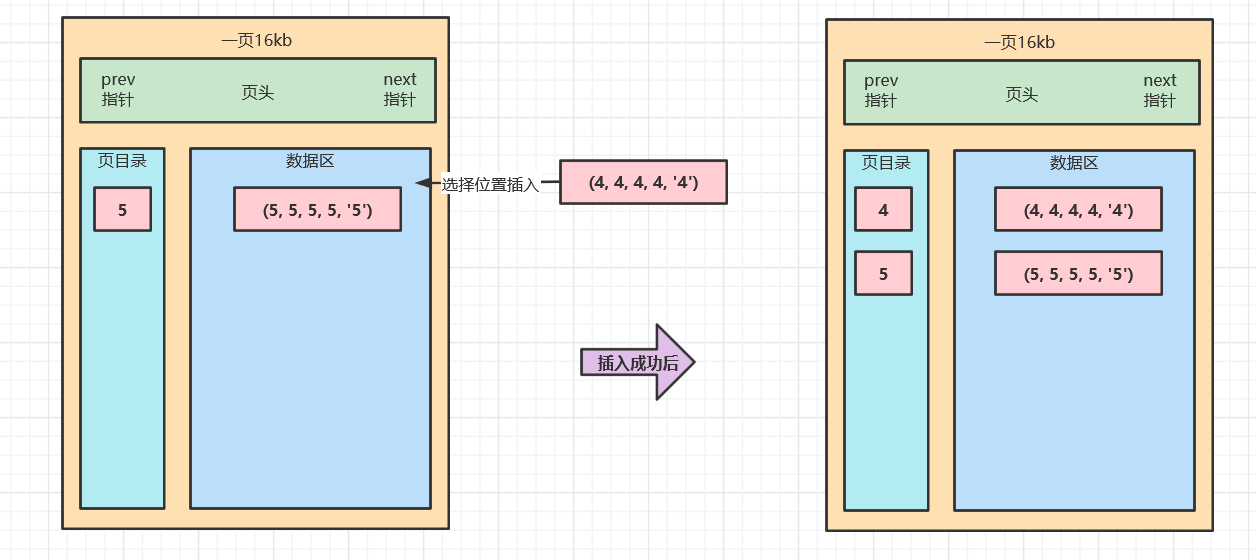
正因为插入的时候,按照了顺序插入,所以查询的时候就可以按照顺序输出。
那么我们看看select * from test where id = 6这条语句是什么情况,大家虽然都知道这段查询语句会走主键索引,但却不知道主键索引到底为何物。先看看explain的解释
1 | explain select * from test where id = 6; |

好可以看到是语句是直接走的主键索引的,这个没什么问题。
至于索引为何物?如果我们有一大本新华字典,里面的汉字是我们的数据,那我们是通过什么去快速查询到想要的字的呢?是通过目录,我们通过新华字典的目录去查询到对应汉字所在的页数,从而快速的检索。
在MySQL中,索引就是目录,它记录了一个指针,一个指向真正存储用户数据的一个内存地址。这就是索引的简单解释,不急,会继续深入的。
所以,在上面的描述下,知道了select * from test where id = 6这段查询语句是通过查询页目录从而去获取到一整行数据的。
刚刚只讲到了一个节点,也就是一页。一页的容量大小是16kb,随着数据的插入,这一页数据总会被插满的,那时B+树会发生什么变化呢?
答案很明显,就是再开一页。这里我们假设,每一页可以存5条数据,总数有20条,那么就是四页,来看看效果图
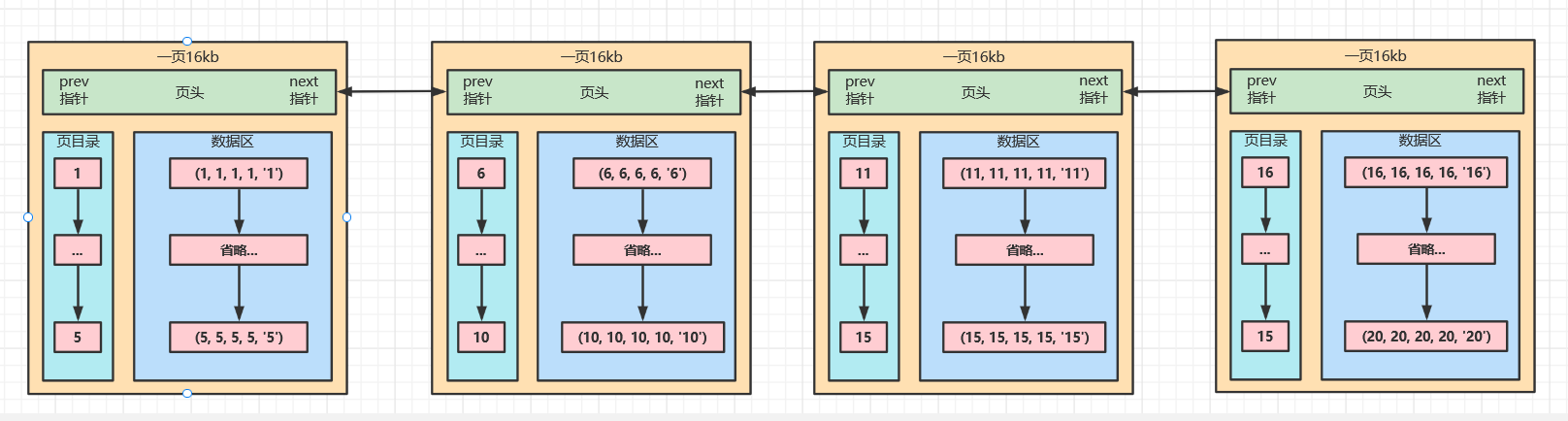
现在我们将执行select * from test where id = 20,如果只是上面的这种结构的话,执行上面那段语句,Innodb会怎么去查找id=20的数据?
难道是取出第一页,查询页目录,一直往后找页目录,直到找到为止?这才简简单单的20条数据啊,如果出现成百万千万的数据,不得查询老半天,而且每一次读取页,都是16kb的磁盘IO,很耗时间。这样的索引结构不行,那么是否还有一些没有考虑到的地方呢?
不要忘记了,Innodb使用的B+树结构,现在只是出现了存储用户数据的叶子节点,枝节点和根节点还什么都没有出来呢?那么这些节点存什么东西呢?重新来看看图
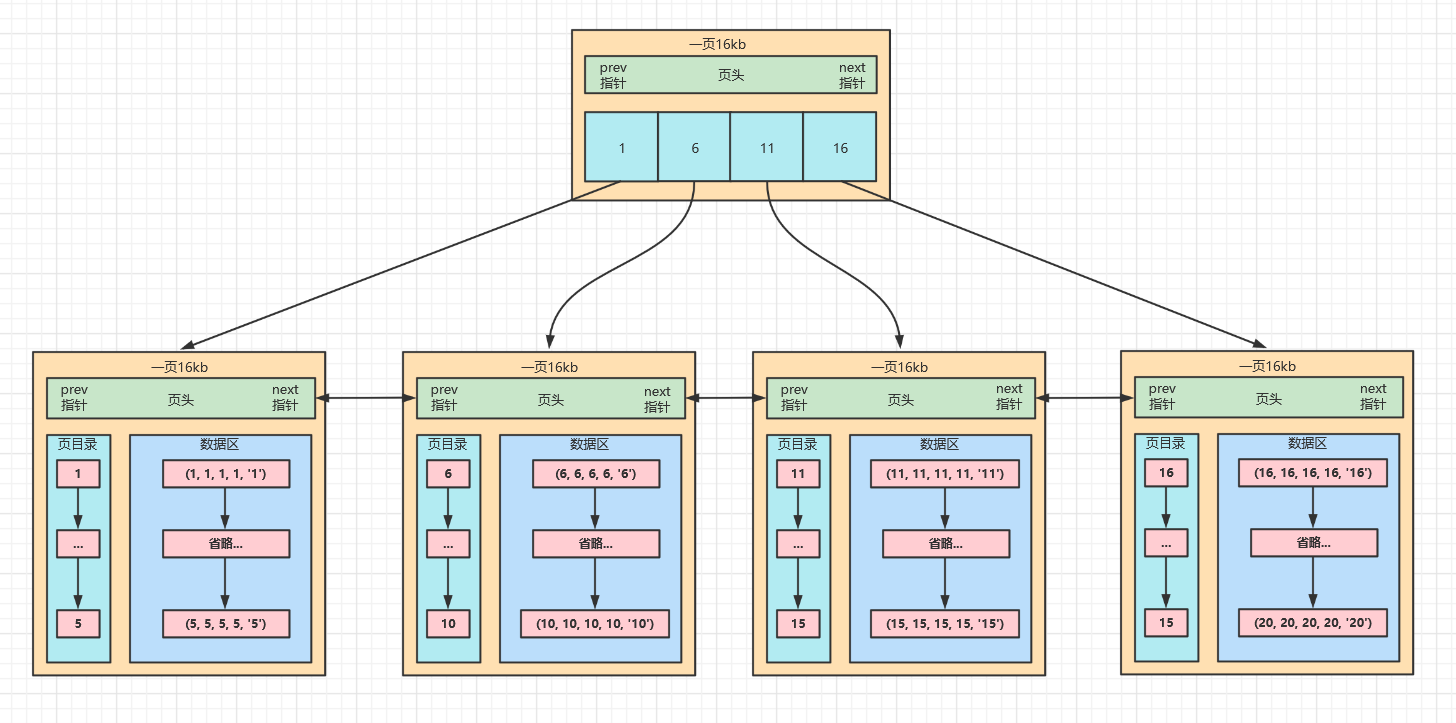
这是两层结构的B+树,那么针对上面那条sql语句select * from test where id = 20,只需要取出根节点,就知道了下一个要去第四页去取自己想要的数据。
如此一来就大大的降低了遍历页目录的时间,这就是索引的魅力。
所以
Innodb中,B+树是怎么存储数据的,就一目了然了叶子节点主要存储用户数据,非叶子节点存储索引数据。其中它们还存有一些页头信息,用来标注和互相引用
事实上,每一页的存储的数据远不止5条,但效果是一样的。都是先去根节点找到下一个叶子节点该去哪里,找到对应的页,再对页中的页目录进行遍历,就能很快的找到自己想要的数据了。
4)B+树可以存储多少的数据
假设Innodb中的这个B+树是三层的,那么我们只需要计算一页能够存储多少个主键,因为每一个主键记录的都是下一层节点页目录的开始的主键。
假设这个主键是int类型的,int占用4个字节,指针指向下一层占用6个字节。那么根节点16kb可以存储多少个主键记录呢?
1638个主键记录,那么也就是说,第二层可以有1638个枝节点。而枝节点的结构和根节点一致,也是1638个主键记录。所以第三层的叶子节点该有多少个
好的那这样的话,我们将有268万的叶子节点,接下来只需要再算出叶子节点一页可以存储多少条数据就可以了。
这得根据表的大小来看,假设一条用户数据占用1kb,我们再忽略页头的那点占用,那就是一页可以存储
我们再计算所有的叶子节点和每页存储的数量
所以得到答案,在我们理想以及假设的情况下,一共可以存储4000万的数据
在真实的开发情况中,主键不一定是int,也可能是bigint,那样的话,只需要重新计算叶子节点的个数。
根据上面的情况来看,MySQL不要使用UUID做主键的原因就是在这里。原本int可以指向很多个子节点,UUID由于占用大,指向子节点的数量大大降低,一个三层B+数存储数据的数量也会大大降低。而且UUID是无序的,这将带来插入的性能问题。
如果不想被人知道系统的数据量,推荐雪花算法生成的主键ID吧,看着挺乱,但是确是有序的,占用与bigint一样。
5)索引类型
按功能来分,我们可以分为普通索引、唯一索引、主键索引和全文索引
按数据存储来分,我们可以分为聚集索引和非聚集索引
5.1)按功能来分
普通索引
先看普通索引,这是作用于普通列的索引,没有其他的约束。这种索引的创建,就是为了提高查询的效率
它的创建语句是
1 | # 创建表时,直接指定普通索引 |
通过上面的创建语句,将额外多出的一个以a字段作为索引列的B+树。
唯一索引
唯一索引和普通索引的区别就是,普通索引的字段是普通字段而来的,而唯一索引的字段是有唯一性约束的。
它的创建语句是
1 | # 创建表时,直接指定唯一索引 |
通过上面的创建语句,将额外多出一个以a字段作为索引列的B+树。
主键索引
主键索引,是指定主键创建的索引。
这个主键列最大的特点是唯一且不能为空,而上面的唯一索引它是允许null值的存在的。
一张表最多只有一个主键索引,不过我们可以选择多个字段作为主键。
创建主键的语句不需要多说,每张表都应该要有
1 | CREATE TABLE `test` ( |
全文索引
老实说,如果是真的想用全文搜索的功能,建议是使用ElasticSearch。
MySQL确实也有全文索引的功能,但在使用时,得注意一下MySQL的版本。
-
MySQL5.6及以前:只有
MyISAM才支持全文索引 -
MySQL5.7以后:
Innodb才开始支持全文索引 -
MySQL5.7.6:在刚开始,
Innodb支持英文的分词索引。在此版本之后,才开始支持中文的全文分词索引
创建语句是
1 | # 创建表时,直接指定全文索引 |
注意一下,全文索引只能作用在
char、varchar、text等的文本字段上才行
5.2)按数据存储来分
什么是数据存储,大家都知道Innodb是按B+树来进行存储的,那就是看B+树的叶子节点上存储的数据是什么。
聚集索引
根据上面这个特性,主要看B+树的叶子节点存储的是否是完整的行数据,那就可以判断出这个B+树是不是聚集索引了。
最典型的聚集索引就是主键索引,通过主键就能找到完整的数据行。
但是,千万要理清楚,主键索引一定是聚集索引,但聚集索引不一定是主键索引。
万一这个表没有指定主键呢?所以会出现以下这种情况
-
如果表定义了主键,将使用主键索引作为聚集索引
-
没有定义主键,将会使用该表第一个唯一且非空的字段作为聚集索引
-
如果上面两个都没有,
Innodb内部将会产生一个隐藏6个字节的列,使用这个列作为聚集索引
非聚集索引
除去聚集索引,剩下的就被成为非聚集索引了。
所以与聚集索引不同的是,非聚集索引的叶子节点存储的不再是完整的行数据,而是主键值。
一段查询sql,用到了这个非聚集索引的话,先找到这个B+树叶子节点的主键值,再根据这主键值,去查询主键索引。
虽然不一定是主键索引,存的也不一定是主键值。但这个过程被称为回表,也就是查询了两棵不同的B+树。这也是非聚集索引又被称为辅助索引或者二级索引的原因。
一张表只有一个聚集索引,不过可以有多个非聚集索引。
在查询时,尽量走聚集索引,聚集索引的速度快。而在走非聚集索引时,尽量控制查询的字段就是非聚集索引的列,避免去回表。
在插入时,二者都会进行重新计算排序,这也是聚集索引推荐自增主键的原因,数据往后添加即可,避免重新计算排序。
6)索引失效的场景
在平常使用查询时,还常常会出现一些不走索引的场景,也就是全表扫描。
全表扫描,这是查询的大忌,导致了慢查询,所以查看下面这段些查询sql,判断下他们会不会走索引
首先,把现在的表结构和数据给大家罗列一下
1 | CREATE TABLE `test` ( |
简单点来看,一个主键索引,三个普通索引,表中有9条数据。
开始以下几道sql,能不能用到索引
| 序号 | 查询sql | 是否走索引 | 说明 |
|---|---|---|---|
| 1 | select * from test where id = 6 | 主键索引 | |
| 2 | select * from test where id > 3 | 主键索引 | 先找到3,再返回后面所有的数据。 同理,主键ID范围查找直接走主键索引 |
| 3 | select * from test where a = 3 | index_a | 走自己定义的index_a普通索引需要经历一次回表 |
| 4 | select b, c, d from test where b = 3 and c = 3 and d = ‘333’ | index_b_c_d | 走自己定义的index_b_c_d普通索引b和c是索引的记录的列,所以不需要经历回表 |
| 5 | select b, c, d from test where c = 3 and d = ‘333’ | 全表扫描 | 不遵循最左前缀原则,故索引不生效 |
| 6 | select b, c, d from test where b = 3 and d = ‘333’ | index_b_c_d | 遵循最左前缀原则 就算c字段不存在,只要b字段存在就行 |
| 7 | select b, c, d from test where d = ‘333’ and b = 3 | index_b_c_d | 遵循最左前缀原则 查询sql的where条件顺序不重要,只需要保证b存在就行 |
| 8 | select * from test where b >= 1 | 全表扫描 | 情况特殊,单独说说 |
| 9 | select * from test where d like ‘%3%’ | 全表扫描 | 模糊匹配全表扫描 |
| 10 | select * from test where d like ‘3%’ | index_d | 模糊右匹配,支持索引 |
| 11 | select * from test where d = 333 | 全表扫描 | 隐式转换会导致索引失效 |
| 12 | select * from test where d is not null | 全表扫描 | not null 导致全表扫描 |
| 13 | select * from test where d != ‘444’ | 全表扫描 | != 导致全表扫描 |
差不多了,就这么几条。
前面2条都很好理解,走的是主键索引。
回表
第3条,在index_a的B+树上找到主键ID,再通过主键ID去查询到所有的列。同理,第4、5、6、7条,查询的列在索引的B+树上就完全存在,所以不需要再进行回表。
最左匹配原则
where条件中查询的列,一定要有索引中定义的最左的字段,才能使用到这个索引。顺序不重要,就像第7条。所以只要出现了b字段,就可以使用到index_b_c_d这个索引。
模糊匹配
第9、10条,这个模糊匹配,分为左右模糊匹配,就是看%出现的位置,只要它不出现在开头,这个查询就可以走到对应的索引。
第8条:特殊的情况
先看下第8条的查询语句,select * from test where b >= 1

这是为什么,按理来说第8条是和第2条是一样的,找到指定的数,再返回后面所有的数。然而实际上,竟然是全表扫描???
这里很简单,就一个原因回表,正是因为回表,导致了Innodb不再去走index_b_c_d的索引。
你想啊,条件b >= 1的数据一共有9条,如果要走index_b_c_d索引的话,还需要回表9次,这就相当于绕路了。
所以在范围查询除去主键的普通列时,尽量避免查询所有列,也就是select *
不信就来试试,这次只查索引中有的字段,select b, c, d from test where b >= 1

隐式转换
在11条中,d字段定义的是字符串,而sql中是用数字进行查询的。这里会进行隐式转换,从而导致索引失效

不等于、不包含
在12、13条中,使用到了!=、not null的条件,这些条件会导致索引失效。类似的条件还有<>、!<、!>、not exists、not in、not like,避免使用上述的条件。
三、最后
MySQL的存储,索引的结构,说简单也简单。说难点,MySQL自身的瓶颈也就在那了,想突破确实困难。
一般来说,Innodb的B+树往往3层是就是顶天了,往4层开始,这个查询速度就会非常的慢。具体一个3层的B+树,可以存储多少的数据量,大家可以根据自己定义的表字段大小,对每一页进行计算,估算出存储的数据量。
对于分库分表,我只是知道一些概念的东西。前路漫长,我只是在追逐前人的脚步罢了。
我是半月,祝你幸福!!!










